Ai improving AI in AI ProgrammingI'm building my multimodal system with modular AI models. I then realized that I need long-term memory to make this much more effective as a companion bot. So, I asked ChatGpt to solve this problem. Code |
| 3 Comments | Started October 19, 2024, 01:30:48 am |
Atronach's Eye in Home Made RobotsGuess I haven't started a project thread for this one yet? Anyway, I put a bunch of work into the mechanical eyeball this year. It's been tougher to get it working perfectly than I expected (when is it not?), but I'm getting closer. Lots of photos and design discussion in the blog, so much I won't try to copy it all here: https://writerofminds.blogspot.com/2023/11/atronachs-eye-2023.html |
| 8 Comments | Started November 21, 2023, 06:39:37 pm |
Running local AI models in AI ProgrammingI'm using Lm Studio as a server and have used it as an app as well, but the LLMs out there are outstanding! They are getting smaller and are competitive with online solutions like Replika! Also, the ability to operate these without NSFW filters makes them great when plotting to rob banks or murders! LoL Or at least creating a script or novel along those lines, even horror and intimacy interactions are off the charts! |
| 3 Comments | Started October 04, 2024, 11:51:42 pm |
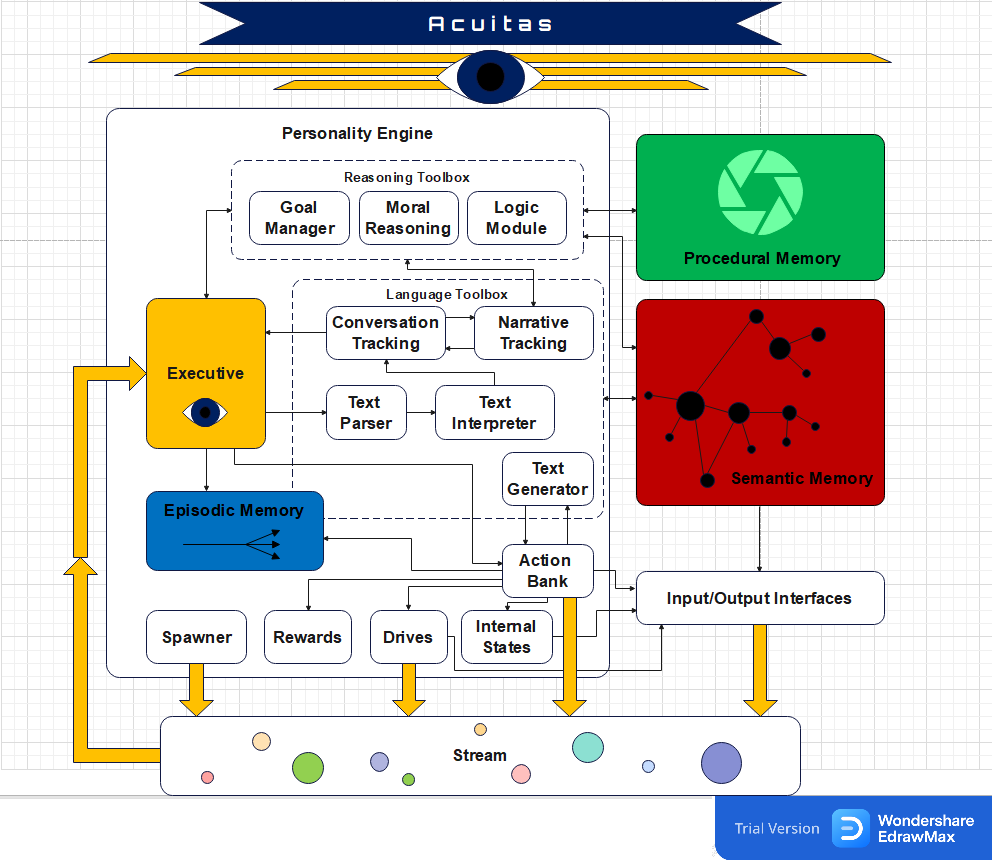
Project Acuitas in General Project DiscussionBlock diagram of Acuitas, the symbolic cognitive architecture: |
| 299 Comments | Started June 02, 2017, 03:17:30 pm |
Hi IM BAA---AAACK!! in Home Made Robots
|
| 10 Comments | Started August 19, 2024, 03:35:32 am |
LLaMA2 Meta's chatbot released in AI Newshttps://ai.meta.com/llama/ Quote This release includes model weights and starting code for pretrained and fine-tuned Llama language models — ranging from 7B to 70B parameters. Scores 80.2 on the Winogrande benchmark. Benchmarks are listed in the first URL. Very similar politician/spokes-person style to both ChatGPT and Google Bard. |
| 8 Comments | Started July 25, 2023, 08:47:36 am |
ollama and llama3 in AI NewsAccess to generative artificial intelligence just changed radically and for the better. Until recently our options were to use online services which were potentially very expensive and almost certainly heavily restricted, or to try to use open source models locally which required high end hardware to operate and which produced disappointing and mediocre results at best. |
| 5 Comments | Started July 10, 2024, 02:17:07 am |
Attempting Hydraulics in Home Made RobotsI made a little home-built hydraulics system and did a writeup on it. It is NOT very capable yet, but it's a bare bones demo with my rather jury-rigged choice of parts. |
| 4 Comments | Started October 10, 2023, 09:24:23 pm |
Server Upgrade in Welcome to AI Dreams forum.Hi folks, I'm in the process of upgrading the server that's hosting this forum so it may be temporarily inaccessible for short periods of time in the coming days. I'll keep the disruptions to a minimum. |
| 1 Comment | Started August 12, 2024, 05:25:31 am |
Reasoner.js: a framework for generalized theory synthesis in General Project Discussionthe idea implementation Co-rewrite takes an input file, an arbitrary metaprogram, and constructs an output file from the input file using the metaprogram. The metaprogram is actually a set of formulas similar to those in math science with the difference that the Co-rewrite formulas may transform not only math expressions, but also any kind of language expression. It is possible to feed to Systelog a formula in a form of f(program(input) -> output) -> program where function program is being automatically constructed and returned by higher order function f, provided that we know what input -> output mappings hold. The language goals are having minimal design, beginner friendly documentation, conveniently generating completely functional executable, multiplatform development environment, multiplatform runtime environment, and self hosting compiler. progress In this thread I plan to keep a log about the progress in programming the Systelog language for which I plan to be open sourced and hosted publicly on GitHub. Of course, I'd be delighted to hear any comments or to answer any questions in the same thread. Project homepage is at : https://github.com/contrast-zone/co-rewrite |
| 25 Comments | Started November 10, 2022, 10:25:26 am |






Talbot, the chatbot in Chatbots - EnglishTalbot is a free and funny chatbot, you can use it if you are bored and no friends are available to chat: he will answer you anytime and anywhere! Understands Italian, Portuguese, English and Spanish.
|
| May 15, 2023, 15:49:22 pm |

I'm Your Man in Robots in MoviesDr Alma Felser, an archaeologist, arrives at a dance club where an employee introduces her to Tom. Alma quizzes Tom on a complex math problem and on trivial details about his favourite poem, and he answers readily. Tom then invites Alma to dance but suddenly begins repeating himself; he is quickly carried away, revealing him to be a robot. |
| Oct 23, 2022, 22:10:45 pm |

WIFELIKE in Robots in MoviesA grieving detective in the near future (Jonathan Rhys Meyers) hunts down criminals who trade artificial humans on the black market. In the fight to end AI exploitation, an underground resistance attempts to infiltrate him by sabotaging the programming of the artificial human assigned as his companion (Elena Kampouris) to behave like his late wife. She begins to question her reality as memories of a past life begin to surface in a world where nothing is as it seems. |
| Oct 17, 2022, 01:52:13 am |

AI Love You in Robots in MoviesThe film is set in a world where Artificial Intelligence (AI) controls most buildings. One such AI, named Dob, controls a corporate tower where a woman named Lana (Pimchanok Luevisadpaibul) works, falls in love with her after a software glitch. The AI then hijacks the body of a man, Bobby (Mario Maurer) and tries to win Lana's affections. |
| Oct 08, 2022, 07:16:50 am |

Brian and Charles in Robots in MoviesBrian lives alone in a remote village in the countryside. Something of an outcast, he spends his spare time inventing things out of found objects in his garage. Without friends or family to rely on, Brian decides to build a robot for company. 'Charles' is not only Brian's most successful invention, but he appears to have a personality all of his own and quickly becomes Brian's best friend, curing his loneliness and opening Brian's eyes to a new way of living. However, Charles creates more problems than Brian bargained for, and the timid inventor has to face-up to several issues in his life; his eccentric ways, a local bully, and the woman he's always been fond of but never had the nerve to talk to. |
| Sep 30, 2022, 00:10:14 am |

Space Sweepers in Robots in MoviesAfter snatching a crashed space shuttle in the latest debris chase, Spaceship Victory's crew members find a 7-year-old girl inside. They realise that she's the humanlike robot wanted by UTS Space Guard. |
| Sep 29, 2022, 20:24:53 pm |

Robot Takeover: 100 Iconic Robots of Myth, Popular Culture & Real Life in BooksIn Robot Takeover, Ana Matronic presents 100 of the most legendary robots and what makes them iconic - their creators, purpose, design and why their existence has shaken, or in some cases, comforted us. Through 100 iconic robots - from Maria in Fritz Lang's Metropolis to the Sentinels of The Matrix and beyond, via the Gunslinger (Westworld), R2-D2 (Star Wars) etc. - this is a comprehensive look at the robot phenomenon. As well as these 100 entries on specific robots, there are features on the people who invent robots, the moral issues around robot sentience, and the prevalence of robots in music, art and fashion, and more. It's the only robot book you need. With fighters, seducers and psychos in their ranks, it's best you get ready for the robot revolution. Know your enemy... |
| Sep 26, 2022, 21:08:48 pm |

The Mandalorian in Robots on TVThe Mandalorian is an American space western television series created by Jon Favreau for the streaming service Disney+. It is the first live-action series in the Star Wars franchise, beginning five years after the events of Return of the Jedi (1983), and stars Pedro Pascal as the title character, a lone bounty hunter who goes on the run to protect "the Child". |
| Sep 26, 2022, 20:45:35 pm |

Lost in Space (2018) in Robots on TVLost in Space is an American science fiction streaming television series following the adventures of a family of space colonists whose ship veers off course. The series is a reboot of the 1965 series of the same name, inspired by the 1812 novel The Swiss Family Robinson. |
| Sep 19, 2022, 01:04:37 am |

Person of Interest in Robots on TVPerson of Interest is an American science fiction crime drama television series that aired on CBS from September 22, 2011, to June 21, 2016. The series centres on a mysterious, reclusive billionaire computer programmer, Harold Finch (Michael Emerson), who has developed a computer program for the federal government known as "the Machine", capable of collating all sources of information to predict terrorist acts and to identify people planning them. The series raises an array of moral issues, from questions of privacy and "the greater good" to the concept of justifiable homicide and problems caused by working with limited information programs. |
| Sep 19, 2022, 00:52:30 am |

Better Than Us in Robots on TVBetter Than Us is a 2018 Russian science fiction television series created by Andrey Junkovsky about an advanced empathic android named Arisa. The story takes place in 2029, in a world where androids serve humans in various positions, even replacing them in many menial jobs. |
| Sep 19, 2022, 00:38:20 am |