First on the worklist for this month was some improved reasoning about action conditions -- specifically, which things need to be true for someone to do an action (prerequisites) and which things, if true, will prevent the action (blockers). Technically, it was already somewhat possible for Acuitas to manage reasoning like this -- ever since I expanded the C&E database to handle "can-do" and "cannot-do" statements, he could be taught conditionals such as "If <fact>, an agent cannot <action>." But the idea of prerequisites and blockers seems to me fundamental enough that I wanted to make it more explicit and introduce some specific systems for handling it.
This was a lot of groundwork that should make things easier in the future, but didn't produce many visible results. The one thing I did get out of it was some improved processing of the "Odysseus and the Cyclops" story. My version of the story contains this line near the end:
"Polyphemus could not catch Odysseus."
Your average human would read that and know immediately that Polyphemus' plan to eat Odysseus has been thwarted. But for Acuitas before now, it was something of a superfluous line in the story. I had to include "Odysseus was not eaten." after it to make sure he got the point ... and though he recorded Odysseus' problem as being solved, he never actually closed out Polyphemus' goal, which caused him to sometimes complain that the story was "unfinished."
With the new prerequisite machinery, these problems are solved. I dropped a conditional in the C&E database: if an agent cannot catch someone, the agent does not have them. And the action "eat" carries a prerequisite that, to eat <item>, you must first have <item>. The new prerequisite-checking functions automatically conclude that Polyphemus' goal is now unachievable, and update it accordingly.
Project #2 was more benchmarking for the Parser. I finished putting together my second childrens' book test set, consisting of sentences from Tron Legacy tie-in picture book Out of the Dark. The Parser's initial "correct" score was around 25%. By adding some common but previously-unknown words (like "against" and "lying") and hints about their usual part-of-speech to Acuitas' database, I was able to improve the score to about 33% ... very close to last month's score on The Magic School Bus: Inside the Earth.
One of the most common errors I saw was failure to distinguish prepositional adverbs from regular prepositions.
The parser by default was treating each word as either a preposition only or an adverb only, depending on which usage was marked as more common. So I added some procedures for discriminating based on its position and other words in the sentence. (The one construction that's still tricky is "Turn on the light" ... I think I know how to handle this one, but need to implement tracking of transitive and intransitive verbs first.) With the help of these new features I was able to get both test sets scoring over 40% correct.
I also downloaded Graphviz at infurl's suggestion (thanks) and wrote code to convert my parser outputs into Graphviz' input language. This makes it much easier to visualize similarities and differences between the parser's output and the human-understood structure of a sentence. Here's a couple sample images! The blog has more, plus links to download the full test results if you so desire:
https://writerofminds.blogspot.com/2021/07/acuitas-diary-39-july-2021.htmlA good result:
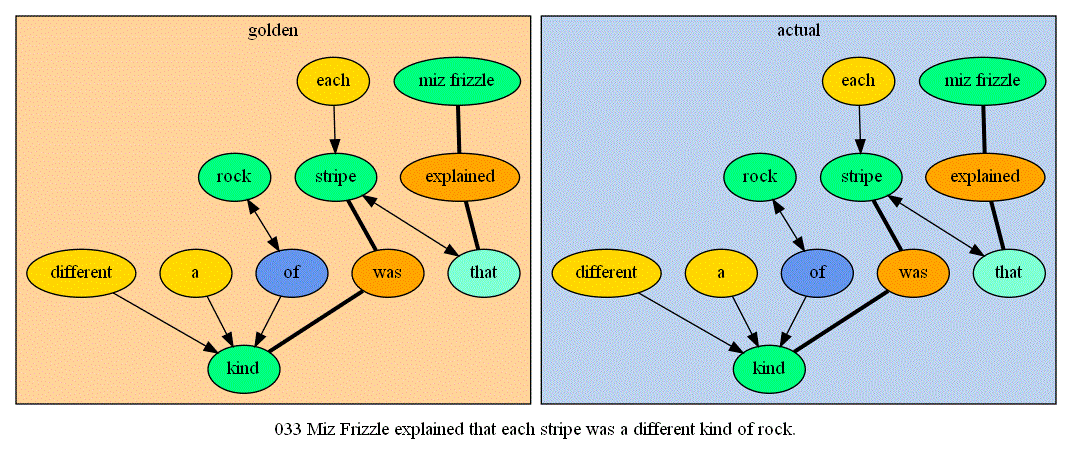
And a ridiculous failure:
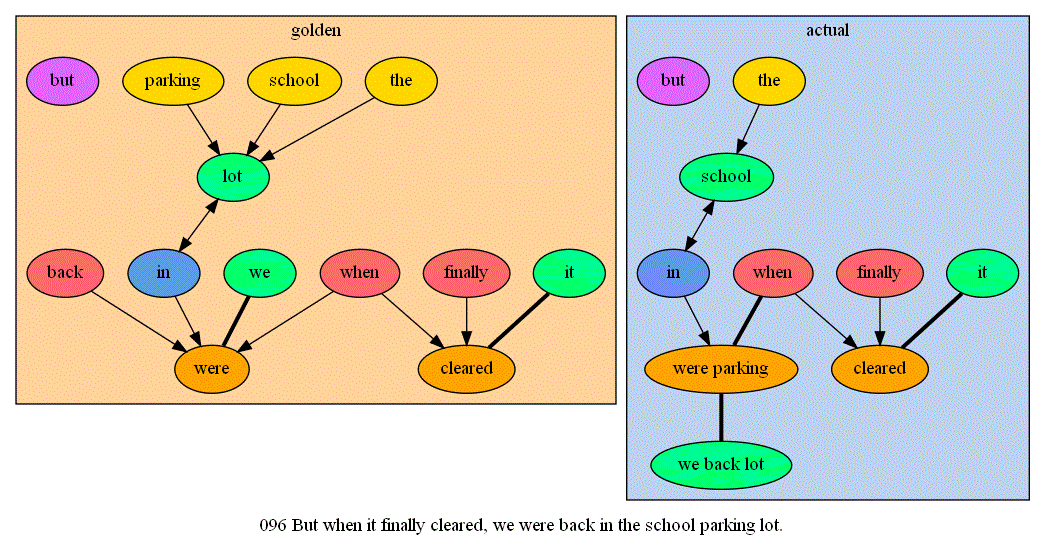
 Poll
Poll